Building a DeepSpeed Docker image for Kubernetes cluster
Motivation of building a DeepSpeed Docker Image
DeepSpeed is one of the best solutions for the model-parallel training of deep learning model. To unleash the full power of our Kubernetes GPU cluster, we need a DeepSpeed docker image. Unfortunately, the DeepSpeed docker hub repository is not well maintained. The latest DeepSpeed points to something pushed two years ago. The Docker “latest” is a lousy design I recommend everyone avoid. For reasons, see here; basically, it’s just a problematic default option instead of an actual pointer to the latest image.
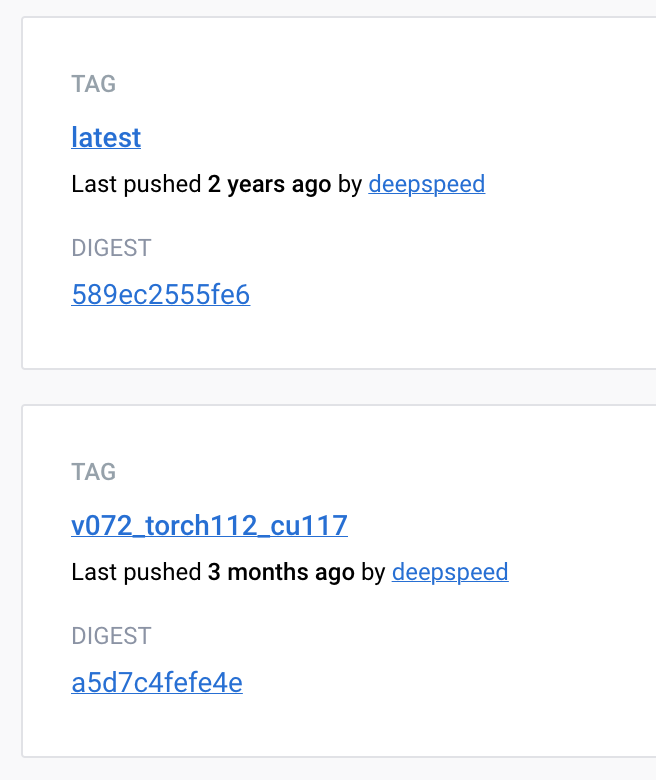
The last commit to the Dockerfile of the git repo was two years ago.
The actual latest (v072_torch112_cu117, though three months ago) official DeepSpeed image uses outdated pyprof, such that the running log is full of future warnings.
FutureWarning: pyprof will be removed by the end of June, 2022
warnings.warn("pyprof will be removed by the end of June, 2022", FutureWarning)This also gives rise to runtime error of the NCCL communicator when running a deepspeed program that operates normally on a bare metal GPU server. It is seemingly due to a headers mismatch.
RuntimeError: [2] is setting up NCCL communicator and retreiving ncclUniqueId from [0] via c10d key-value store by key '0', but store->get('0') got error: Connection reset by peer
Traceback (most recent call last):
File "mnist_ds.py", line 123, in <module>
print(f'[{dist.get_rank()}] Total time elapsed: {main()} seconds')
File "mnist_ds.py", line 91, in main
torch.distributed.barrier()
File "/opt/conda/lib/python3.8/site-packages/torch/distributed/distributed_c10d.py", line 2811, in barrier
work = default_pg.barrier(opts=opts)Also, the DeepSpeed official image does not have all extension ops installed.
--------------------------------------------------
DeepSpeed C++/CUDA extension op report
--------------------------------------------------
NOTE: Ops not installed will be just-in-time (JIT) compiled at
runtime if needed. Op compatibility means that your system
meet the required dependencies to JIT install the op.
--------------------------------------------------
JIT compiled ops requires ninja
ninja .................. [OKAY]
--------------------------------------------------
op name ................ installed .. compatible
--------------------------------------------------
cpu_adam ............... [YES] ...... [OKAY]
cpu_adagrad ............ [NO] ....... [OKAY]
fused_adam ............. [YES] ...... [OKAY]
fused_lamb ............. [YES] ...... [OKAY]
sparse_attn ............ [YES] ...... [OKAY]
transformer ............ [YES] ...... [OKAY]
stochastic_transformer . [YES] ...... [OKAY]
async_io ............... [YES] ...... [OKAY]
utils .................. [YES] ...... [OKAY]
quantizer .............. [NO] ....... [OKAY]
transformer_inference .. [YES] ...... [OKAY]
spatial_inference ...... [NO] ....... [OKAY]
--------------------------------------------------
DeepSpeed general environment info:
torch install path ............... ['/usr/local/lib/python3.8/dist-packages/torch']
torch version .................... 1.13.0+cu117
torch cuda version ............... 11.7
torch hip version ................ None
nvcc version ..................... 11.7
deepspeed install path ........... ['/usr/local/lib/python3.8/dist-packages/deepspeed']
deepspeed info ................... 0.7.6+21105521, 21105521, master
deepspeed wheel compiled w. ...... torch 1.13, cuda 11.7So it seems necessary to build the DeepSpeed-PyTorch docker image ourselves.
Example Dockerfile
FROM nvidia/cuda:11.7.1-devel-ubuntu20.04
##############################################################################
# Temporary Installation Directory
##############################################################################
ENV STAGE_DIR=/tmp
RUN mkdir -p ${STAGE_DIR}
##############################################################################
# Installation/Basic Utilities
##############################################################################
ENV DEBIAN_FRONTEND=noninteractive
ENV TZ=America/Los_Angeles
RUN apt-get update && \
apt-get install -y --no-install-recommends \
software-properties-common build-essential autotools-dev \
nfs-common pdsh \
cmake g++ gcc \
curl wget vim tmux emacs less unzip \
htop iftop iotop ca-certificates openssh-client openssh-server \
rsync iputils-ping net-tools sudo \
llvm-11-dev
##############################################################################
# Installation Latest Git
##############################################################################
RUN add-apt-repository ppa:git-core/ppa -y && \
apt-get update && \
apt-get install -y git && \
git --version
##############################################################################
# Client Liveness & Uncomment Port 22 for SSH Daemon
##############################################################################
# Keep SSH client alive from server side
RUN echo "ClientAliveInterval 30" >> /etc/ssh/sshd_config
RUN cp /etc/ssh/sshd_config ${STAGE_DIR}/sshd_config && \
sed "0,/^#Port 22/s//Port 22/" ${STAGE_DIR}/sshd_config > /etc/ssh/sshd_config
##############################################################################
# Mellanox OFED
##############################################################################
ENV MLNX_OFED_VERSION=5.7-1.0.2.0
RUN apt-get install -y libnuma-dev
RUN cd ${STAGE_DIR} && \
wget -q -O - http://www.mellanox.com/downloads/ofed/MLNX_OFED-${MLNX_OFED_VERSION}/MLNX_OFED_LINUX-${MLNX_OFED_VERSION}-ubuntu20.04-x86_64.tgz | tar xzf - && \
cd MLNX_OFED_LINUX-${MLNX_OFED_VERSION}-ubuntu20.04-x86_64 && \
./mlnxofedinstall --user-space-only --without-fw-update --all -q && \
cd ${STAGE_DIR} && \
rm -rf ${STAGE_DIR}/MLNX_OFED_LINUX-${MLNX_OFED_VERSION}-ubuntu20.04-x86_64*
##############################################################################
# nv_peer_mem
##############################################################################
ENV NV_PEER_MEM_VERSION=1.3
ENV NV_PEER_MEM_TAG=1.3-0
RUN mkdir -p ${STAGE_DIR} && \
git clone https://github.com/Mellanox/nv_peer_memory.git --branch ${NV_PEER_MEM_TAG} ${STAGE_DIR}/nv_peer_memory && \
cd ${STAGE_DIR}/nv_peer_memory && \
./build_module.sh && \
cd ${STAGE_DIR} && \
tar xzf ${STAGE_DIR}/nvidia-peer-memory_${NV_PEER_MEM_VERSION}.orig.tar.gz && \
cd ${STAGE_DIR}/nvidia-peer-memory-${NV_PEER_MEM_VERSION} && \
apt-get update && \
apt-get install -y dkms && \
dpkg-buildpackage -us -uc && \
dpkg -i ${STAGE_DIR}/nvidia-peer-memory_1.2-0_all.deb
##############################################################################
# OPENMPI
##############################################################################
ENV OPENMPI_BASEVERSION=4.1
ENV OPENMPI_VERSION=${OPENMPI_BASEVERSION}.4
RUN cd ${STAGE_DIR} && \
wget -q -O - https://download.open-mpi.org/release/open-mpi/v${OPENMPI_BASEVERSION}/openmpi-${OPENMPI_VERSION}.tar.gz | tar xzf - && \
cd openmpi-${OPENMPI_VERSION} && \
./configure --prefix=/usr/local/openmpi-${OPENMPI_VERSION} && \
make -j"$(nproc)" install && \
ln -s /usr/local/openmpi-${OPENMPI_VERSION} /usr/local/mpi && \
# Sanity check:
test -f /usr/local/mpi/bin/mpic++ && \
cd ${STAGE_DIR} && \
rm -r ${STAGE_DIR}/openmpi-${OPENMPI_VERSION}
ENV PATH=/usr/local/mpi/bin:${PATH} \
LD_LIBRARY_PATH=/usr/local/lib:/usr/local/mpi/lib:/usr/local/mpi/lib64:${LD_LIBRARY_PATH}
# Create a wrapper for OpenMPI to allow running as root by default
RUN mv /usr/local/mpi/bin/mpirun /usr/local/mpi/bin/mpirun.real && \
echo '#!/bin/bash' > /usr/local/mpi/bin/mpirun && \
echo 'mpirun.real --allow-run-as-root --prefix /usr/local/mpi "$@"' >> /usr/local/mpi/bin/mpirun && \
chmod a+x /usr/local/mpi/bin/mpirun
##############################################################################
# Python
##############################################################################
ENV PYTHON_VERSION=3
RUN apt-get install -y python3 python3-dev && \
rm -f /usr/bin/python && \
ln -s /usr/bin/python3 /usr/bin/python && \
curl -O https://bootstrap.pypa.io/get-pip.py && \
python get-pip.py && \
rm get-pip.py && \
pip install --upgrade pip && \
# Print python an pip version
python -V && pip -V
RUN pip install pyyaml
RUN pip install ipython
##############################################################################
# Some Packages
##############################################################################
RUN apt-get update && \
apt-get install -y --no-install-recommends \
libsndfile-dev \
libcupti-dev \
libjpeg-dev \
libpng-dev \
screen \
libaio-dev
RUN pip install psutil \
yappi \
cffi \
ipdb \
pandas \
matplotlib \
py3nvml \
pyarrow \
graphviz \
astor \
boto3 \
tqdm \
sentencepiece \
msgpack \
requests \
pandas \
sphinx \
sphinx_rtd_theme \
scipy \
numpy \
sklearn \
scikit-learn \
nvidia-ml-py3 \
mpi4py \
cupy-cuda11x
##############################################################################
## SSH daemon port inside container cannot conflict with host OS port
###############################################################################
ENV SSH_PORT=2222
RUN cat /etc/ssh/sshd_config > ${STAGE_DIR}/sshd_config && \
sed "0,/^#Port 22/s//Port ${SSH_PORT}/" ${STAGE_DIR}/sshd_config > /etc/ssh/sshd_config
##############################################################################
# PyTorch
##############################################################################
ENV PYTORCH_VERSION=1.13.0
ENV TORCHVISION_VERSION=0.14.0
ENV TENSORBOARDX_VERSION=2.5
RUN pip install torch==${PYTORCH_VERSION}
RUN pip install torchvision==${TORCHVISION_VERSION}
RUN pip install tensorboardX==${TENSORBOARDX_VERSION}
##############################################################################
# PyYAML build issue
# https://stackoverflow.com/a/53926898
##############################################################################
RUN rm -rf /usr/lib/python3/dist-packages/yaml && \
rm -rf /usr/lib/python3/dist-packages/PyYAML-*
##############################################################################
# DeepSpeed
##############################################################################
RUN git clone https://github.com/microsoft/DeepSpeed.git ${STAGE_DIR}/DeepSpeed
RUN pip install triton==1.0.0
RUN cd ${STAGE_DIR}/DeepSpeed && \
git checkout . && \
git checkout master && \
DS_BUILD_OPS=1 pip install .
RUN rm -rf ${STAGE_DIR}/DeepSpeed
RUN python -c "import deepspeed; print(deepspeed.__version__)" && ds_report
WORKDIR /rootAnalyzing the Dockerfile
The Base image
The Base image is chosen to be the Nvidia official CUDA 11.7 image nvidia/cuda:11.7.1-devel-ubuntu20.04. By the time this is written, CUDA 11.8 image is already out, but PyTorch’s PyPI prebuilt binary still depends on CUDA 11.8 runtime. Installing PyTorch through PyPI will then overwrite some default 11.8 runtimes of the image and result in inconsistency like
Traceback (most recent call last):
File "fc_model_sub_episodes.py", line 278, in <module>
main()
File "fc_model_sub_episodes.py", line 101, in main
predict(module, module.test_dataloader(), num=3)
File "fc_model_sub_episodes.py", line 264, in predict
states, actions = xb['states'].cuda(), xb['actions'].cuda()
File "/home/andriy/miniconda3/envs/my_proj/lib/python3.7/site-packages/torch/cuda/__init__.py", line 153, in _lazy_init
torch._C._cuda_init()
RuntimeError: cuda runtime error (804) : forward compatibility was attempted on non supported HW at /opt/conda/...when running torch.cuda.is_available(). We cannot rmmod nvidia modeset in an image or reboot in an image; thus, this is not fixable.
Using Anaconda or default Python
I chose to use the default Python instead of Python installed by Anaconda. Anaconda is preferred when we need multiple environments, but it is not useful in a docker image. Anaconda has its own builder executables such that it contaminates the executable namespace. When compiling something, sometimes we need to manually remove the conda-build’s ld and use the system’s default ld. Otherwise, we need to install conda GCC and GXX, and set the environment variable CC and XX. (e.g. when compiling the mpi4py)
After installing Anaconda, the DeepSpeed’s default PyPI compilation raises
fatal error: cuda_profiler_api.h: No such file or directory
16 | #include <cuda_profiler_api.h>
| ^~~~~~~~~~~~~~~~~~~~~
compilation terminated.it might be resolvable by checking all needed environment variables. But without Anaconda, life is much easier.
llvm-11-dev
llvm-14-dev is not included in the apt default repo of Ubuntu 20.04 and 18.04. Generally, LLVM version does not matter too much here.
Mellanox OFED
You may notice that the build module is hard-coded to nvidia-peer-memory_1.2-0_all.deb, while the version above is 1.3. It is because the git commit tagged 1.3 does not update the build target name yet. Probably the problem can be resolved in the future.
Python version
The DeepSpeed sparse attention OP requires triton==1.0.0 (which is pretty outdated), which is a DeepLearner compiler by OpenAI. Triton at 1.0.0 only supports up to Python 3.8, which is the default Python version in apt of Ubuntu 20.04 anyways. (If we use Ubuntu 22.04 — then the default version becomes 3.10, and it needs to be taken care).
Consequences of using latest Python:
ERROR: Could not find a version that satisfies the requirement triton==1.0.0 (from deepspeed) (from versions: 0.1, 0.1.1, 0.1.2, 0.1.3, 0.2.0, 0.2.1, 0.2.2, 0.2.3, 0.3.0)
ERROR: No matching distribution found for triton==1.0.0 Is it possible to compile triton from source using Python 3.10?
The short answer is no. See this.
In file included from /tmp/pip-install-obn59lgk/triton_554ba834927346c39cc8dbfe997907a0/src/include/triton/codegen/analysis/axes.h:4,
from /tmp/pip-install-obn59lgk/triton_554ba834927346c39cc8dbfe997907a0/src/lib/codegen/analysis/axes.cc:1:
/tmp/pip-install-obn59lgk/triton_554ba834927346c39cc8dbfe997907a0/src/include/triton/tools/graph.h:18:20: error: ‘size_t’ was not declared in this scope; did you mean ‘std::size_t’?
18 | typedef std::map<size_t, std::vector<node_t>> cmap_t;
| ^~~~~~
| std::size_tDeepSpeed
We use DS_BUILD_OPS=1 to make sure all extension OPs are installed, unlike the official one.
WSL: Building the Docker Image
If you are using WSL and want to use the Docker image in a GPU cluster, don’t use the Nvidia runtime for building. This may sound weird, but if you follow the steps here, that is to make Nvidia runtime the default runtime, you will find the image loses access to nvidia-smi in the cluster
> nvidia-smi
NVIDIA-SMI couldn't find libnvidia-ml.so library in your system. Please make sure that the NVIDIA Display Driver is properly installed and present in your system.
Please also try adding directory that contains libnvidia-ml.so to your system PATH.It still works perfectly on your personal workstation, after you run docker run --gpus=all. Take a deeper look, the root cause could be
inside the Kube container > cat libcuda.so
[nothing]An educated guess is that the WSL Nvidia container runtime makes the libcuda.so a stub (instead of a real library), such that the docker faithfully records it as an empty file in the image. The built image, therefore, loses key CUDA software.
Once a Windows NVIDIA GPU driver is installed on the system, CUDA becomes available within WSL 2. The CUDA driver installed on Windows host will be stubbed inside the WSL 2 as libcuda.so, therefore users must not install any NVIDIA GPU Linux driver within WSL 2. One has to be very careful here as the default CUDA Toolkit comes packaged with a driver, and it is easy to overwrite the WSL 2 NVIDIA driver with the default installation. We recommend developers to use a separate CUDA Toolkit for WSL 2 (Ubuntu) available here to avoid this overwriting. This WSL-Ubuntu CUDA toolkit installer will not overwrite the NVIDIA driver that was already mapped into the WSL 2 environment. To learn how to compile CUDA applications, please read the CUDA documentation for Linux.
What if I Already Create /etc/docker/daemon.json?
Change /etc/docker/daemon.json to {} and restart the docker. Build with no-cache option to make sure the empty file does not stay in the previous steps’ cache.
Result
--------------------------------------------------
DeepSpeed C++/CUDA extension op report
--------------------------------------------------
NOTE: Ops not installed will be just-in-time (JIT) compiled at
runtime if needed. Op compatibility means that your system
meet the required dependencies to JIT install the op.
--------------------------------------------------
JIT compiled ops requires ninja
ninja .................. [OKAY]
--------------------------------------------------
op name ................ installed .. compatible
--------------------------------------------------
cpu_adam ............... [YES] ...... [OKAY]
cpu_adagrad ............ [YES] ...... [OKAY]
fused_adam ............. [YES] ...... [OKAY]
fused_lamb ............. [YES] ...... [OKAY]
sparse_attn ............ [YES] ...... [OKAY]
transformer ............ [YES] ...... [OKAY]
stochastic_transformer . [YES] ...... [OKAY]
async_io ............... [YES] ...... [OKAY]
utils .................. [YES] ...... [OKAY]
quantizer .............. [YES] ...... [OKAY]
transformer_inference .. [YES] ...... [OKAY]
spatial_inference ...... [YES] ...... [OKAY]
--------------------------------------------------
DeepSpeed general environment info:
torch install path ............... ['/usr/local/lib/python3.8/dist-packages/torch']
torch version .................... 1.13.0+cu117
torch cuda version ............... 11.7
torch hip version ................ None
nvcc version ..................... 11.7
deepspeed install path ........... ['/usr/local/lib/python3.8/dist-packages/deepspeed']
deepspeed info ................... 0.7.6+21105521, 21105521, master
deepspeed wheel compiled w. ...... torch 1.13, cuda 11.7The built image does not include redundant CUDA, has no warnings, and has all extension OPs.
Test set: Average loss: 0.0533, Accuracy: 9842/10000 (98%)
[0] Total time elapsed: 15.861084461212158 seconds
[3] Total time elapsed: 15.8411705493927 seconds
[2] Total time elapsed: 15.914736032485962 seconds
[1] Total time elapsed: 15.69409441947937 secondsRunning an MNIST benchmark, DeepSpeed is much faster than other frameworks such as Horovod and DDP (which costs more than 20 seconds with 4 GPUs)
Sidenote
I have tried building the DeepSpeed docker image using Nautilus Gitlab CI instead of my home workstation. The result is terrible.
Nautilus Gitlab image upload is very, very slow.
See this reference: Gitlab registry push extremely slow.
Pushing new images to Gitlab takes forever. I try a docker file that creates an empty directory in nvidia/cuda image (mkdir), and pushing it takes 76 minutes 37 seconds. The Kaniko docker image does not provide a pushing progress bar. Therefore I can hardly tell the speed. Given that the CUDA image size is ~2GB, pushing a large ML Anaconda image may take a whole night.
Hostname Resolution in Nautilus is unstable
Sometimes the git clone fails because it cannot DNS lookup github.com.
Cloning into 'nautilus_tutorial'...
fatal: unable to access 'https://github.com/Rose-STL-Lab/nautilus_tutorial.git/': Could not resolve host: github.com
/bin/bash: line 1: cd: nautilus_tutorial: No such file or directoryDataset download may fail and cause subsequence model training and testing to fail as well.
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ./data/MNIST/raw/train-images-idx3-ubyte.gz
Failed to download (trying next):
<urlopen error [Errno -3] Temporary failure in name resolution>
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/train-images-idx3-ubyte.gzThe most annoying is the Kanoki builder may fail to resolve Gitlab (which is in the same cluster)… It would be more than terrifying to build something that requires a network connection and takes several hours with Nautilus.
[2022-11-21 19:27:42,769] [WARNING] [runner.py:179:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.